Overview
Large Language Models (LLMs) are rapidly becoming the fundamental unit of computation — powering reasoning, generation, and increasingly, retrieval. While modern Information Retrieval (IR) systems already leverage LLMs for contextual ranking, they often treat them as black boxes, relying on general intelligence but ignoring structural efficiency.
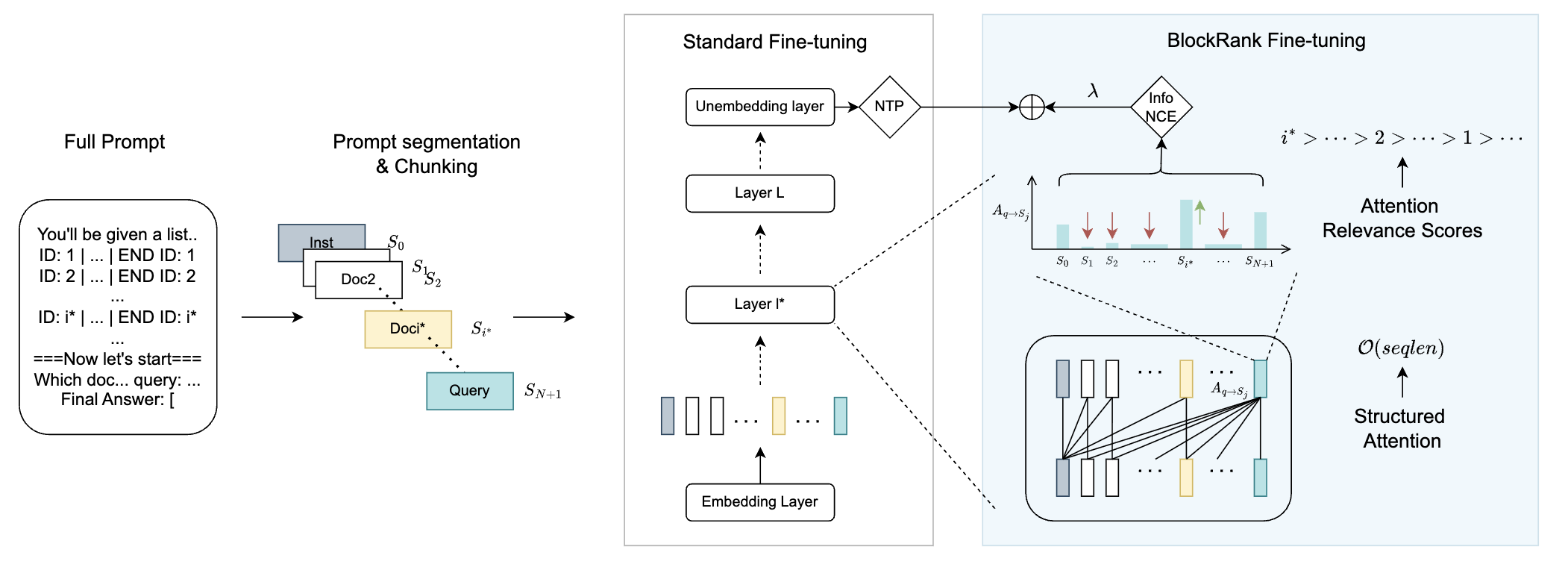
BlockRank (Blockwise In-context Ranking) is a specialized architecture and fine-tuning approach for scalable in-context retrieval and ranking. It’s built on two key insights about LLMs fine-tuned for ranking tasks:
Inter-document block sparsity → Attention is dense within each document but sparse across documents — meaning full quadratic attention is unnecessary.
Query-token retrieval signals → Certain query tokens (e.g., delimiters) encode strong relevance signals in their attention patterns during the prefill stage.
Key Ideas
Based on these observations, BlockRank modifies both the architecture and training of an LLM:
Structured Sparse Attention
Enforces attention only within document blocks and to shared instruction tokens, cutting complexity from quadratic → linear.Auxiliary Contrastive Attention Loss
Adds a mid-layer contrastive objective to directly optimize query–document attention, improving both relevance and interpretability.Attention-based Inference
Uses attention maps (from the prefill stage) to compute document relevance scores directly — eliminating the need for auto-regressive decoding.
Results Summary
- Strong zero-shot generalization on BEIR, matches or outperforms state-of-the-art listwise rankers (e.g., RankZephyr, FIRST)
- 4.7× faster inference on MSMarco (100 documents) compared to standard decoding based implementation
- Scales linearly with in-context documents
- Works with existing open LLMs (e.g., Mistral, Llama)
Citation
If you find this work useful, please cite:
@article{gupta2025blockrank,
title={Scalable In-context Ranking with Generative Models},
author={Gupta, Nilesh and You, Chong and Bhojanapalli, Srinadh and Kumar, Sanjiv and Dhillon, Inderjit and Yu, Felix},
journal={arXiv preprint arXiv:2510.05396},
year={2025}
}