Overview
LATTICE proposes an LLM-native retrieval paradigm that combines the efficiency of hierarchical search with the reasoning power of modern large language models. Instead of relying on a static retriever + reranker pipeline or attempting to place a large corpus directly in an LLM context, LATTICE organizes the corpus into a semantic tree and uses an LLM as an active search agent that navigates that tree. This design yields logarithmic search complexity while preserving the LLM’s ability to perform nuanced, multi-step relevance judgments for complex, reasoning-heavy queries. Below we provide a sample interactive visualization of LATTICE search.
Interactive sample prediction
Interactive Plotly view of a LATTICE search over a semantic tree: the tree root is at the top and document leaves are at the bottom.
- Yellow path = ground-truth route to the relevant document(s).
- Green intensity = node path relevance (darker = higher relevance).
- Hover callouts show the LLM’s local score, calibrated latent score, child scores, and the model’s reasoning (chain-of-thought) used when expanding that node.
Use the visualization to quickly see which branches the agent prioritized, inspect calibration effects (local vs. calibrated scores), and read the LLM’s justification for traversal decisions.
Key ideas
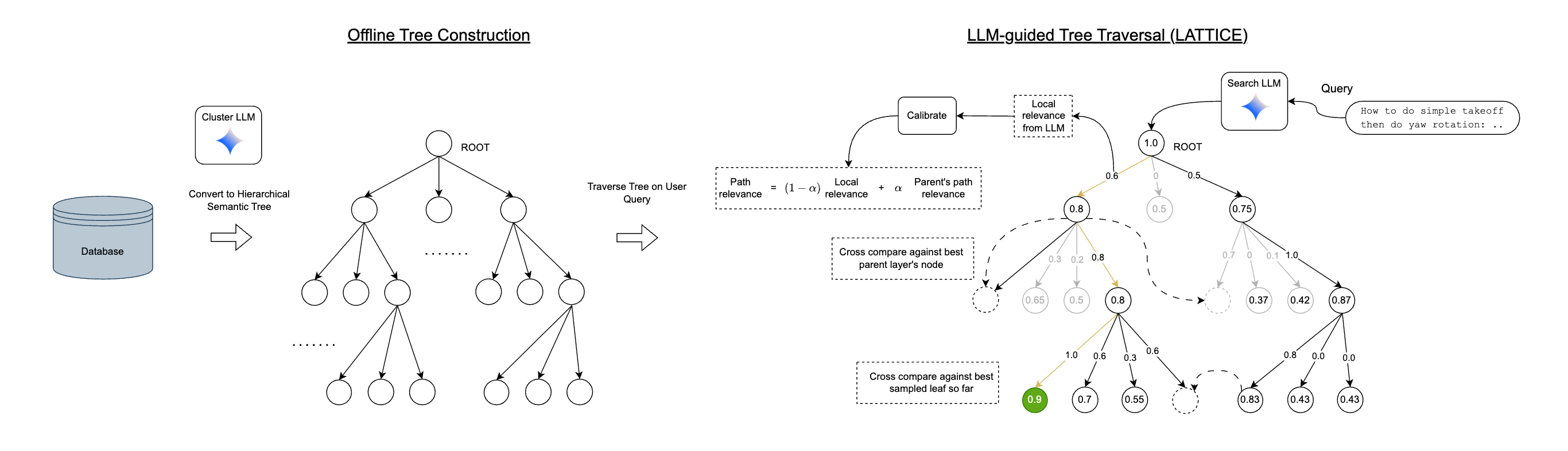
- Semantic tree index → The corpus is structured offline into a hierarchy of internal nodes (LLM-generated summaries) and leaf nodes (documents). This tree constrains the search space and makes traversal efficient.
- LLM-guided traversal → At query time, a search LLM reasons and scores small candidate slates of sibling nodes along with some calibration nodes. These local judgments drive a best-first traversal (beam expansion) instead of flat reranking.
- Global calibration → LLM scores are context-dependent and noisy, LATTICE estimates latent relevance scores and aggregates it into a path relevance score (smoothed via a momentum α) so nodes across branches are comparable.
- Two tree construction strategies:
- Bottom-up — agglomerative clustering and LLM summarization (good when passages belong to larger source documents);
- Top-down — LLM-driven divisive clustering using multi-level summaries (better when documents are conceptually distinct).
Why it matters
- Efficiency → Traversing a semantic tree can require fewer LLM evaluations than reranking long flat lists; search cost grows roughly logarithmically with corpus size.
- Reasoning-aware retrieval → The search LLM’s in-context reasoning allows retrieval to capture deeper, multi-step relevance signals that simple embeddings or keyword matchers miss.
- Distillation potential → The LATTICE framework can be used to generate high-quality training data for training smaller retrievers.
- Interpretable retrieval → The tree structure and LLM reasoning traces provide insights into why certain documents were retrieved.
Results
Ranking results on BRIGHT
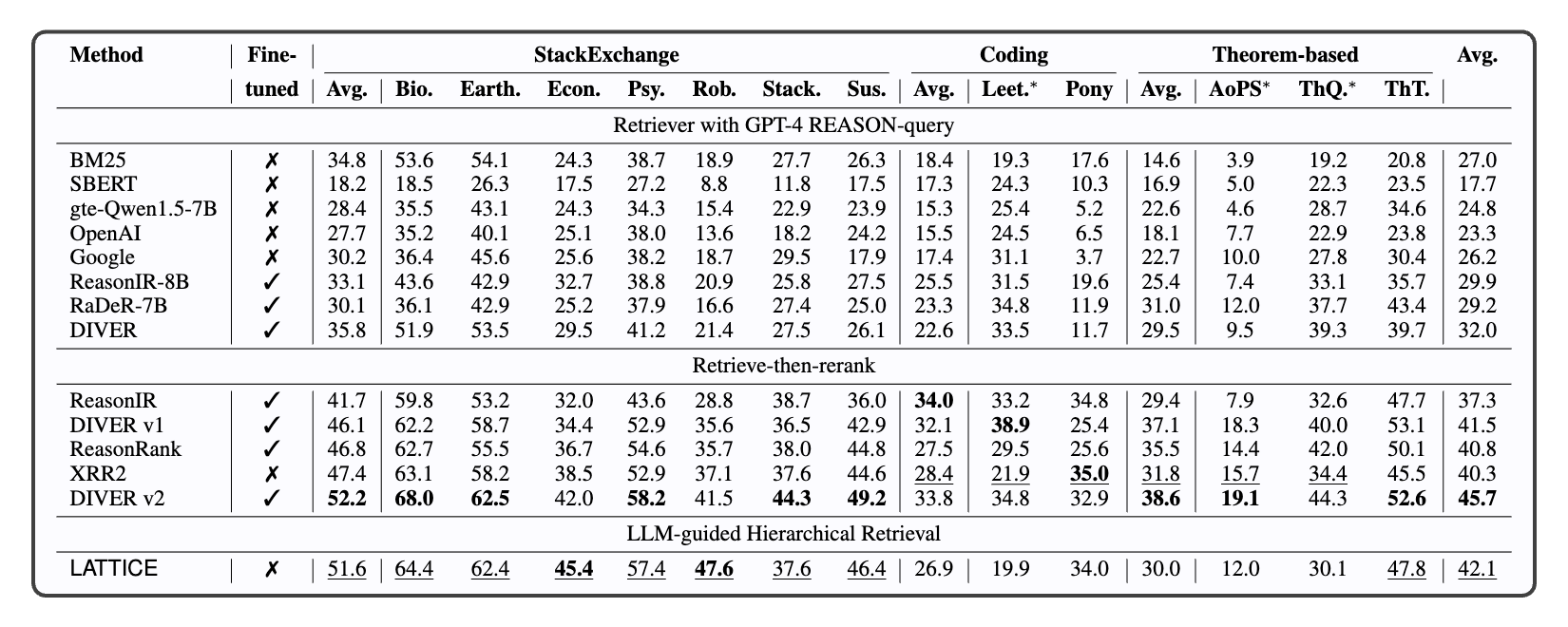
NDCG@10 performance of various retrievers and rankers on the BRIGHT benchmark. Bold represents overall best numbers, underline represents best numbers among zero-shot methods, ∗ denotes subsets with dynamic corpus.
In the seven StackExchange datasets, which use a standard static corpus, LATTICE achieves an average nDCG@10 of 51.6, significantly outperforming the controlled reranking baseline XRR2’s score of 47.4. Furthermore, our zero-shot performance is highly competitive with the fine-tuned SOTA, Diver-v2 (52.2), and even achieves the best results in several sub-domains like Economics and Robotics.
On the 3/5 Coding and Theorem-based tasks (LeetCode, AoPS & TheoremQ), our method’s performance is noticably lower than the baselines. This is attributable to a specific benchmark artifact: the use of a query-dependent dynamic corpus, where a unique large list (can be > 10K) of documents (which are potential positives) is excluded from the search space. While we prune the excluded leaf nodes at query time, the pre-computed summaries ($\phi(v)$) of their parent nodes do not update dynamically. Consequently, these summaries often misguide the traversal (please see Figure 6, Section C.2 in paper). In contrast, retrieve-then-rerank pipelines can simply filter excluded documents from their candidate list post-retrieval without penalty. We would like to note that most real-world IR systems operate on a query-independent corpus.
Retrieval results & cost analysis on Stackexchange datasets from BRIGHT
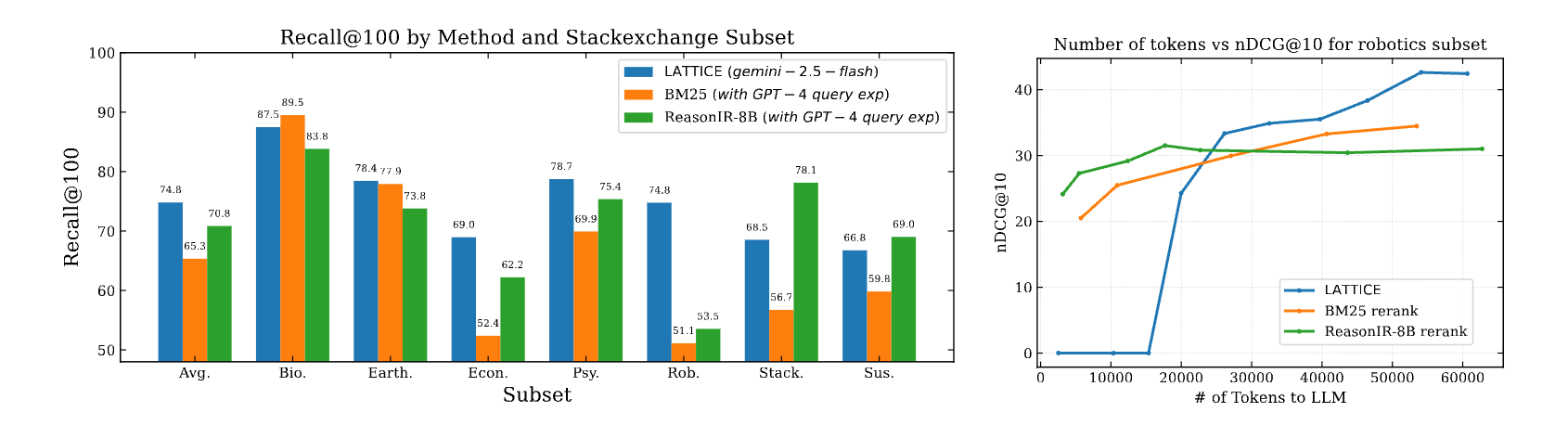
(Left) Recall@100 on BRIGHT’s StackExchange subsets. Comparison between zero-shot LATTICE (Gemini-2.5-flash) against a BM25 retriever (with GPT-4 query expansion) and a fine-tuned dual-encoder ReasonIR-8B (with GPT-4 query expansion). LATTICE yields the highest average recall (74.8%) and substantially outperforms BM25 across all subsets (avg +9.5 pp) and ReasonIR-8B on average (+4.0 pp), with particularly large gains on some datasets like Economics and Robotics.
(Right) LLM cost (measured in avg. number of input tokens given to LLM) vs. ranking quality (nDCG@10) on the Robotics subset. Reranking baselines (BM25+rerank, ReasonIR-8B+rerank) with varying top-k shortlist use same Gemini-2.5-flash as reranker exhibit early gains but quickly plateau. LATTICE starts with a shallow flat region (cost of traversing tree levels) but then scales more effectively—surpassing the baselines and continuing to improve to a higher final nDCG—demonstrating that guided hierarchical traversal using LLM can be more compute efficient too.
Ablation of LATTICE search components

To quantify the contribution of each component of LATTICE, we conduct an ablation study with results presented in the above table. We compare our full method against several variants:
- a version without score calibration (always taking the latest score given by the search LLM to a node)
- one without path relevance calculation, and
- one with zero reasoning budget to the LLM (passing
thinking_budget=0in search LLM calls and strictly constraining it to output only the “scores” field in its output json).
Disabling path relevance smoothing causes the largest degradation, followed by removing either the LLM’s reasoning or score calibration mechanism reducing the average score by over 2.2 nDCG points.
Cite
If you find this work helpful, please cite:
@article{gupta2025lattice,
title={LLM-Guided Hierarchical Retrieval},
author={Gupta, Nilesh and Chang, Wei-Cheng and Bui, Ngot and Hsieh, Cho-Jui and Dhillon, Inderjit S.},
journal={arXiv preprint arXiv:2510.13217},
year={2025}
}